



Artificial Inteligence
Alexander Kronrod, a Russian AI researcher, once said 'Chess is the Drosophila of AI. Pieces and strategic positions have no intrinsic utility in chess; the super goal is winning. For a human, "self" is a powerful, embracing symbol that gathers in the player that is this goal system and part of reality that is inside this mind and the body that sees and moves for this viewpoint. In order to achieve expert human-based strategy, we are creating an AI engine that focuses on strategy of the game, by means of analytical evaluation of the famous players and all games ever played, then distinguishing them from each other, thus pointing out personality and manner. AI engine constantly evaluates the current game cycle and all the algorithms that run in parallel, then it chooses the right strategy for the next move. The only way to lose a game is if a player or an opponent makes a mistake. Perfection is a much harder problem than simply being unbeatable.
Numerical Analytics
New algorithms focused to simplify parallel programming. There are between 1043 and 1050 possible total moves in Chess. A calculated number of total game-tree complexity to be 10120. There are between 0 to 248 moves possible per turn per game calculations. Of these possible moves, N-set series choices made by players utilizing fuzzy logic differential equation algorithms. Furthermore at the higher-maxima all models of games, as Riemannian maps in Hilbert space, have N possible variations per human computing ability parameters minima-maxima. Also, alpha-beta pruning as an improvement over minimax, to find other, unknown, pruning techniques... The approach is from both ends of the table base: opening moves database and end games database. Evaluating all unknown positions at the top hierarchy of the middle game tree and finding a "super move" that will determine whether the match: drawn or won. The goal is 16000 ELO and 32 men-tablebase completed one day. The game of chess can be officially considered a draw if both players play perfectly. The first rule of chess is the last rule of chess: "Two kings can never be placed on adjacent squares".
VOLTA Architecture
After unified virtual memory, giving CPUs access to the speedy memory built into GPUs, and vice versa.In Volta, memory modules are piled atop one another and placed on the same silicon substrate as the GPU core itself. Its called ‚Äėstacked DRAM‚Äô ‚ÄĒ giving these new GPUs access to up to one terabyte per second of bandwidth. That‚Äôs enough to move the equivalent of a full Blu-Ray disc worth of data through a chip in just 1/50th of a second. As of now (Volta Architecture), Tesla V100 for NVLink-Optimized Servers combines 16 GB HMB2 memory with 900 GB/s Memory Bandwidth and up to 120 TeraFLOPS DEEP LEARNING Performance. NVIDIA¬ģ Tesla¬ģ V100 ‚Äď The Most Advanced Data Center Accelerator Ever Built! Titan - K20 accelerated and named one of the world's fastest supercomputers. The Titan supercomputer works with a beastly 18,688+ NVIDIA Tesla K20X GPU accelerator units. NVIDIA GPUDirect for Video technology allows 3rd party tools to communicate directly with NVIDIA GPUs. RDMA is a direct memory access from the memory of one computer into that of another without involving either one's operating system. This permits high-throughput, low-latency networking, which is especially useful if millions of computers world wide interconnect into a huge cluster. This could also beat the performance of Titan.
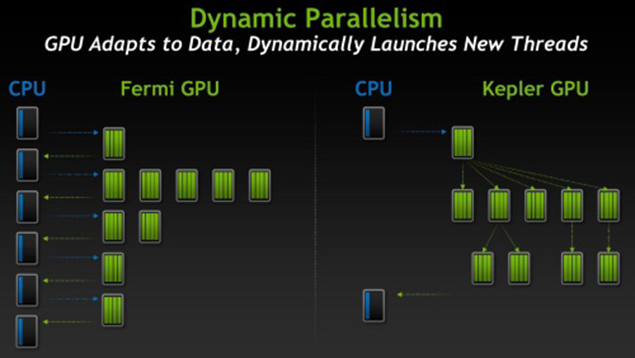
Dynamic Parallelism
Dynamic parallelism is a great feature for GPUs, which allows on-demand spawning of kernels on the GPU without any CPU intervention. However, this feature has two major drawbacks. First, the launching of GPU kernels can incur significant performance penalties. Second, dynamically generated kernels are not always able to efficiently utilize the GPU cores due to hardware-limits. To address these two concerns cohesively, proposed hardware based solution SPAWN - is a runtime framework that controls the dynamically-generated kernels, thereby directly reducing the associated launch overheads and queuing latency. Dynamic parallelism support in CUDA extends the ability to configure and launch grids, as well as wait for the completion of grids, to threads that are themselves already running within a grid.
Pictures







Technology
- RDMA for GPUDirect
- NVIDIA NVLink‚ĄĘ
- Nsight Eclipse Edition
- CUDA BLAS
- Dynamic Parallelism
- Hyper Q
- OpenCL
- MATLAB
- Jacket
- ArrayFire
Newsletter Subscribe
Subscribe and join our mailing list.
Trusted and loved by us:








Please Note, not all technology is revealed yet due to the competitive intelligence and the nature of this fact.